

L’intelligenza artificiale sta raggiungendo la conoscenza umana
I modelli linguistici si stanno sviluppando rapidamente negli ultimi anni. Le loro capacità stanno cambiando completamente il modo in cui possiamo accedere ai dati e alle informazioni, compreso il modo in cui possiamo utilizzarli. Grazie all’intelligenza artificiale e alle reti neurali, questi modelli sono in grado di svolgere molteplici compiti.
- Rispondere alle domande;
- Riassumere e tradurre testi;
- Riconoscere comandi dal testo ed eseguirli;
- Programmare;
- Fare il parsing del testo;
- Eseguire calcoli;
- Chattare;
- Scrivere.
GPT-3 è il modello più famoso, anche se aziende come Meta, Google, Microsoft e NVIDIA stanno investendo in enormi modelli di generazione linguistica. Nello spazio dei modelli linguistici, tuttavia, il leader dell’innovazione DeepMind ha creato qualcosa di veramente notevole: Gopher, un modello linguistico da 280 miliardi di parametri.
Come riportato e secondo lo studio di DeepMind, Gopher riduce il divario tra GPT-3 e le competenze umane, superando le previsioni degli esperti. Gopher surclassa i modelli linguistici di ultima generazione esistenti in circa l’81% dei compiti con risultati comparabili. Ciò risulta particolarmente utile in settori ad alta concentrazione di informazioni, come il fact-checking e la conoscenza generale.
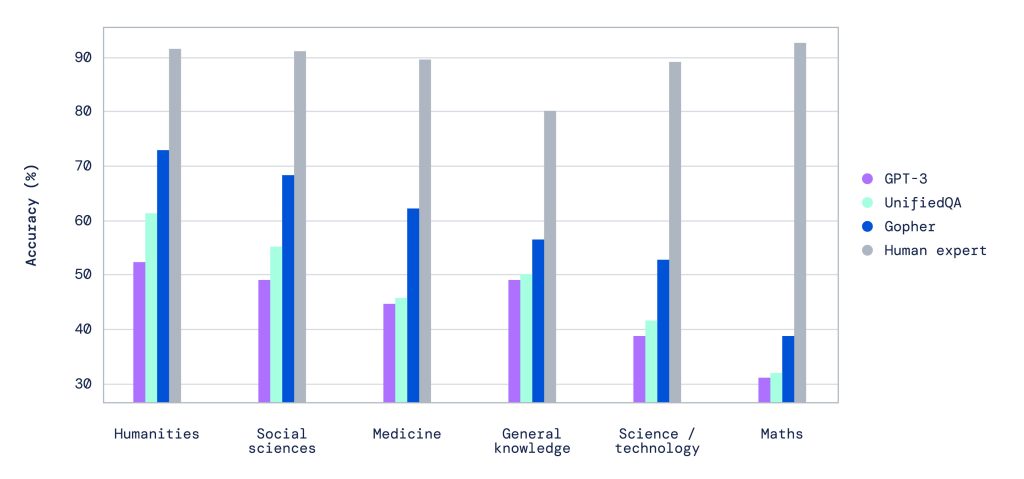
Per diversi compiti cruciali, il team di studio ha scoperto che le capacità di Gopher superano i modelli linguistici esistenti. Tra questi, il benchmark Massive Multitask Language Understanding (MMLU), in cui Gopher mostra un miglioramento significativo rispetto ai lavori precedenti, in termini di prestazioni umane di utenti esperti.

Gopher può rispondere a domande e persino risolvere problemi tratti da esami universitari. Inoltre, è in grado di mantenere il filo del discorso durante una conversazione. Ricorda quindi quando ci si riferisce implicitamente a un argomento precedente e mantiene la coerenza nelle risposte.

Tuttavia, commette ancora alcuni errori.
DeepMind ha pubblicato anche altri due documenti. Il primo si riferisce ai problemi etici e sociali legati ai modelli linguistici di grandi dimensioni, mentre il secondo esamina una nuova architettura più efficiente in termini di addestramento.
I rischi etici e sociali includono:
- discriminazione, esclusione,… (persistenza di stereotipi, discriminazioni ingiuste, norme di esclusione, linguaggio tossico,…);
- danni da informazione (rischi derivanti da fughe di dati privati o dalla deduzione di informazioni sensibili);
- danni da disinformazione (rischi derivanti da informazioni scadenti, false o fuorvianti, anche in ambiti sensibili, e rischi concatenati come la perdita di fiducia nei confronti delle informazioni condivise);
- usi dannosi (rischi derivanti da soggetti che cercano di causare danni);
- danni da interazione uomo-computer (rischi specifici dei soggetti conversazionali che interagiscono con gli utenti umani, tra cui l’uso non sicuro, la manipolazione o l’inganno);
- automazione, accesso e danni ambientali (rischio di danni ambientali, automazione del lavoro e altre sfide che possono avere un effetto disparato su diversi gruppi sociali o comunità).
Secondo il rapporto di ricerca, DeepMind ha addestrato la famiglia di modelli Gopher su MassiveText, una raccolta di grandi dataset di testo in lingua inglese provenienti da varie fonti, come pagine web, libri, notizie e codici. Il filtraggio della qualità dei contenuti, la rimozione del testo ripetitivo, la deduplicazione dei documenti simili e la rimozione dei documenti con una notevole sovrapposizione del set di test fanno parte della pipeline che gestisce i dati. I ricercatori hanno scoperto che, con il progredire della pipeline, le prestazioni del modello linguistico migliorano, sottolineando l’importanza della qualità del set di dati.

MassiveText ha circa 10,5 TB di testo o 2,35 miliardi di documenti. La versione completa di GPT-3 può memorizzare 175 miliardi di parametri di apprendimento automatico. Anche altri colossi tecnologici hanno potenziato i loro algoritmi. Jurassic-1, di AI21 Labs, contiene 178 miliardi di parametri. Quindi, Gopher è significativamente più grande di entrambi, con 280 miliardi di parametri. Tuttavia, è ben lontano dall’essere il più grande.
Microsoft e NVIDIA hanno collaborato per rilasciare il modello Megatron-Turing Natural Language Generation (MT-NLG), che ha 530 miliardi di parametri. Con quasi mille miliardi di parametri, Google ha creato e sottoposto a test di benchmark Switch Transformers, un approccio per l’addestramento dei modelli linguistici. Wu Dao 2.0 ha 1,75 trilioni di parametri, secondo l’Accademia di Intelligenza Artificiale di Pechino (BAAI), sostenuta dal governo cinese.
Per 100 compiti, tuttavia, Gopher supera l’attuale livello più avanzato (81% di tutti i compiti). I modelli linguistici di grandi dimensioni come GPT-3 (175 miliardi di parametri), Jurassic-1 (178 miliardi di parametri) e Megatron-Turing NLG sono inclusi nel modello di base (530 miliardi di parametri).
Gopher è migliorato in modo consistente in tutte le categorie, compresa la comprensione della lettura, le materie umanistiche, l’etica, le materie scientifiche e la medicina. C’è stato anche un miglioramento generale nel fact-checking. I miglioramenti sono minori per i compiti ad alta intensità di ragionamento (come l’Algebra astratta), mentre i test ad alta concentrazione di informazioni mostrano un miglioramento maggiore e più consistente (come la Conoscenza generale).
In 11 delle 19 sfide, Gopher mostra un miglioramento, in particolare nei libri e negli articoli. Si pensa che ciò sia dovuto all’uso eccessivo dei dati dai libri da parte di MassiveText (percentuale di campionamento del 27% rispetto al 16% di GPT-3).
L’intelligenza artificiale sta aumentando il suo potenziale in pochi anni, e presto tutta la conoscenza umana sarà accessibile da una rete neurale come Gopher, in grado di trovare ed elaborare dati in una molteplicità di modi. Sarà più facile scrivere articoli e storie, oltre che svolgere altri compiti come tradurre o riassumere testi. Tuttavia, quando si hanno a disposizione così tanti dati, le possibilità sono infinite. Sarà sicuramente un grande aiuto, ma potrebbe portare a una mancanza di creatività poiché tutti trarranno ispirazione dai dati esistenti piuttosto che creare nuove idee. Inoltre, ci sono dei rischi (alcuni dei quali già menzionati) come quello di fidarsi troppo delle informazioni fornite dall’I.A. senza considerare che potrebbero esserci degli errori o dei dati manipolati che potrebbero portarci ad una falsa concezione della realtà.
