

A.I. is reaching human knowledge
Language models have been quickly developing in the last few years. Their capabilities are completely changing the way we can access data and information, including how we can use them. Thanks to AI and neural networks, these models can also perform multiple tasks.
- Answering questions;
- Summarizing and translating text;
- Recognizing commands from text and executing them;
- Coding;
- Parsing text;
- Calculating;
- Chatting;
- Writing.
GPT-3 is the most famous model, although companies like Meta, Google, Microsoft, and NVIDIA are also investing in huge language generation models. In the language model space, however, innovation leader DeepMind has created something truly remarkable: Gopher, a 280-billion-parameter transformer language model.
As reported and according to DeepMind’s study, Gopher reduces the accuracy gap between GPT-3 and human expert performance and outperforms forecaster expectations. Gopher outperforms existing state-of-the-art language models in around 81% of tasks with comparable outcomes. This is particularly useful in knowledge-intensive sectors such as fact-checking and general knowledge.
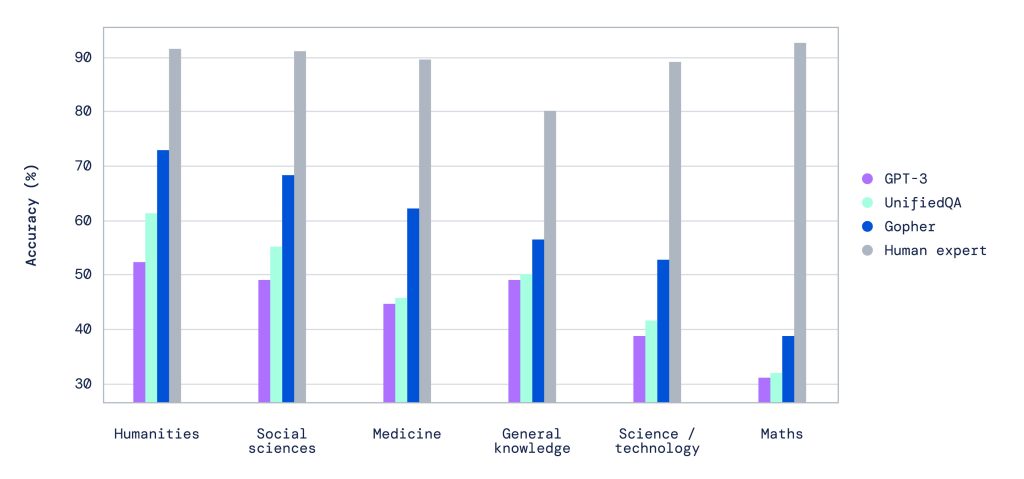
For several crucial tasks, the study team discovered that Gopher’s capabilities outperform existing language models. This includes the Massive Multitask Language Understanding (MMLU) benchmark, in which Gopher shows a significant improvement over previous work in terms of human expert performance.

Gopher can answer questions and even solve problems taken from university exams. In addition, it can keep the line of discussion during a conversation. Therefore, it remembers when we are referring to a previous topic implicitly and keeps coherence in its answers.

However, it still makes some mistakes.
DeepMind also published two other papers. The first refers to the ethical and societal problems connected with huge language models, while the second looks at a novel architecture that is more efficient in terms of training.
Ethical and social risks include:
- discrimination, exclusion, toxicity (perpetuation of stereotypes, unfair discrimination, exclusionary norms, toxic language,…);
- information hazards (risks from private data leaks or correctly inferring sensitive information);
- misinformation harms (risks arising from poor, false, or misleading information including in sensitive domains, and knock-on risks such as the erosion of trust in shared information);
- malicious uses (risks from actors who try to cause harm);
- human-computer Interaction harms (risks specific to underpin conversational agents that interact with human users, including unsafe use, manipulation, or deception);
- automation, access, and environmental harms (risk of environmental harm, job automation, and other challenges that may have a disparate effect on different social groups or communities).
DeepMind trained the Gopher family of models on MassiveText, which is a collection of big English-language text datasets from various sources such as web pages, books, news stories, and code, according to the research report. Content quality filtering, removal of repetitive text, deduplication of similar documents, and removal of documents with considerable test-set overlap are all part of the data pipeline. They discovered that as the pipeline progresses, the performance of the language model improves, underlining the importance of dataset quality.

MassiveText has around 10.5 TB of text or 2.35 billion documents. The full version of GPT-3 can store 175 billion machine learning parameters. Other tech behemoths have been boosting up their algorithms as well. Jurassic-1, from AI21 Labs, contains 178 billion parameters. So, Gopher is significantly larger than both of them, with 280 billion parameters. It is, however, far from being the largest.
Microsoft and NVIDIA collaborated to release the Megatron-Turing Natural Language Generation (MT-NLG) model, which has 530 billion parameters. With almost a trillion parameters, Google created and benchmarked Switch Transformers, an approach for training language models. Wu Dao 2.0 has 1.75 trillion parameters, according to the Chinese government-backed Beijing Academy of Artificial Intelligence (BAAI).
For 100 tasks, however, Gopher outperforms the present state-of-the-art (81% of all tasks). Large language models like GPT-3 (175 billion parameters), Jurassic-1 (178B parameters), and Megatron-Turing NLG are included in the basic model (530 billion parameters).
Gopher improved consistently in all categories, including reading comprehension, humanities, ethics, STEM, and medicine. There was also an overall improvement in fact-checking. It shows fewer improvements for reasoning-intensive tasks (such as Abstract Algebra), whereas knowledge-intensive tests show a bigger and more consistent improvement (such as General Knowledge).
On 11 of 19 challenges, Gopher shows improved modeling, particularly in books and articles. This is thought to be caused by MassiveText’s excessive use of book data (sampling proportion of 27% compared to 16% in GPT-3).
AI is increasing its potential in a few years, and soon all human knowledge will be accessible through a neural network like Gopher, which is able to find and elaborate on data in a variety of ways. It will be easier to write articles and stories, as well as other tasks such as translating or summarizing text. However, when you have so much data available, the possibilities are endless. It will surely be a great help but it could lead to a lack of creativity because everybody will draw inspiration from existing data rather than creating new ideas. In addition, there are risks (some mentioned above), such as trusting too much information provided by the AI without considering that there might be mistakes or manipulated data that could lead us to a false perception of reality.
