
InstructGPT è in grado di eseguire operazioni più specifiche
GPT-3 ha dimostrato di essere il più potente algoritmo di intelligenza artificiale in grado di scrivere qualsiasi genere di testo: dagli articoli alle canzoni ma anche linguaggi di programmazione per programmare. Tuttavia, GPT-3 non è esente da difetti o strani comportamenti provenienti da bias che generano disinformazione.
Anche se è adatto per una vasta gamma di attività linguistiche, è difficile ottenere qualcosa di specifico poiché non si può definire precisamente ciò che si vuole ottenere. Un approccio basato sulla prompt engineering sembrava essere una soluzione perché permette di fornire un input in modo esplicito, dato che la descrizione di un determinato compito è incorporata nel comando stesso, per esempio, una domanda o un ordine, tuttavia risulta abbastanza laborioso per la maggior parte degli utenti.
OpenAI ha ora risolto questa lacuna introducendo una nuova versione della famiglia GPT che raccomandano di utilizzare per tutti i compiti linguistici al posto del GPT-3 originale.
Questa versione di GPT-3 (precedentemente conosciuta come InstructGPT) è ottimizzata per seguire le istruzioni, invece di prevedere la parola più probabile. Questo non solo li rende più facili da usare per la maggior parte delle persone poiché il prompt engineering non è più necessario, ma rende anche i modelli più affidabili e funzionali. La qualità dei completamenti non è dipendente dalle istruzioni fornite come lo era nei modelli GPT-3 originali, evitando così molti errori umani.
Potremmo dire che GPT-3 funziona bene solo quando segue istruzioni indirette o implicite. Non bisogna mai dire a GPT-3 cosa fare direttamente, ma solo implicitamente. Al contrario, InstructGPT può seguire istruzioni esplicite.
OpenAI, d’altra parte, non si è fermata qui. InstructGPT non è solo di gran lunga superiore a GPT-3 nel seguire le istruzioni, ma è anche più in linea con le intenzioni umane. Questa è la sfida dell’allineamento dell’I.A. che rivela le difficoltà di creare sistemi di I.A. che riconoscono i nostri valori, credenze e desideri e agiscono in modo da non interferire con essi, anche se facciamo errori nelle nostre definizioni.
Per convertire i modelli GPT-3 in modelli InstructGPT, OpenAI ha sviluppato una tecnica in tre fasi.
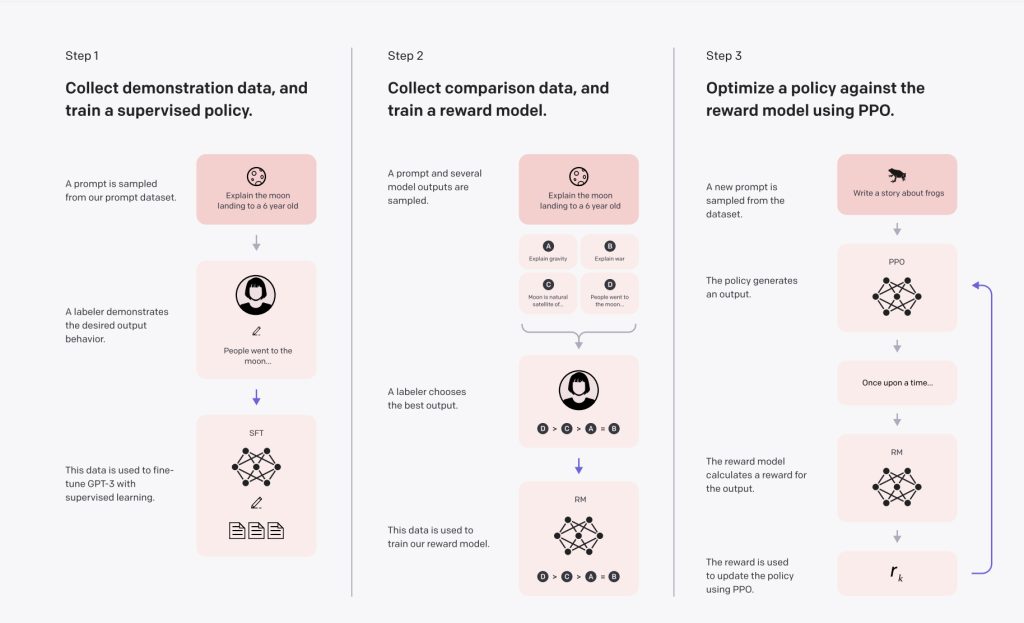
La messa a punto del modello è la fase iniziale per la specializzazione di GPT-3 per una specifica attività. Per fare ciò, hanno creato un set di dati che includeva suggerimenti e completamenti sotto forma di dati riguardanti istruzioni da seguire. Hanno creato un nuovo modello chiamato SFT (supervised fine-tuning) dopo aver addestrato GPT-3 su questo dataset, che ha fornito una linea di base per confrontare il GPT-3 originale con l’InstructGPT finito. Questo modello era comunque migliore di GPT-3 per quanto riguarda il seguire le istruzioni, anche se non necessariamente allineato con le preferenze umane.
Nei due passi successivi, hanno usato una metodologia di apprendimento con rinforzo che hanno sviluppato con DeepMind soprannominata RLHF (apprendimento di rinforzo con feedback umano) per allineare il modello con gli obiettivi umani.

La seconda fase è quella di creare un sistema di ricompensa (RM). Per tradurlo in RM, hanno messo a punto un modello GPT-3 usando un dataset comparativo di 33 mila istruzioni (non lo stesso che hanno usato per addestrare SFT). Il dataset di confronto è composto da coppie di istruzioni con più completamenti per richiesta (4-9), classificati dai classificatori umani dal migliore al peggiore in termini di preferenza. Quando viene dato uno stimolo, l’obiettivo era che la RM imparasse quali completamenti gli umani preferissero.
Nella fase finale, hanno usato l’apprendimento per rinforzo per mettere a punto un modello SFT che fosse già stato messo a punto con il dataset dimostrativo. Poiché impiega un approccio di ottimizzazione prossimale, il modello finale (InstructGPT), è anche conosciuto come PPO-ptx nello studio (ptx significa mix di pre-addestramento poiché l’ultima fase di perfezionamento utilizza anche i dati del dataset di pre-addestramento GPT-3) (PPO). Il RM è usato come funzione di ricompensa nell’algoritmo PPO (questo è il modo in cui si insegna a InstructGPT partendo dal feedback umano).
La procedura di messa a punto dell’ultimo passaggio è la seguente: Quando a InstructGPT viene presentata una richiesta, esso risponde con un completamento. Il risultato viene trasmesso all’ RM, che determina la ricompensa. La ricompensa è data al modello InstructGPT in modo che aggiorni la procedura e si avvicini al risultato che gli umani vorrebbero vedere.
In breve, GPT-3 è messo a punto per seguire prima le istruzioni e poi per accordarsi con le preferenze umane basate sul feedback umano. Questo è InstructGPT.
L’obiettivo di GPT-3 era semplice: “ottenere la parola più probabile in base ai dati che gli sono stati forniti” applicando tecniche ben note di apprendimento automatico e statistica. Tuttavia, è difficile definire ciò che è vantaggioso e innocuo per gli esseri umani. OpenAI intendeva costruire un obiettivo che potesse includere sia intenzioni esplicite (seguire le istruzioni) che implicite (come definito da Amanda Askell e altri): Volevano un modello che fosse utile, onesto e innocuo.
Nell’ambito dei modelli linguistici, l’onestà è difficile da definire poiché questo comportamento è correlato alle credenze interne, che traspaiono poco nei modelli linguistici. E lo stesso vale per ciò che è dannoso (inteso come offensivo, discriminante o forviante).
Così i classificatori sono stati orientati a dare priorità all’utilità nei confronti dell’utente durante l’addestramento, anche se gli utenti desideravano esplicitamente una risposta potenzialmente dannosa, e alla veridicità e innocuità nella valutazione, che hanno cercato di migliorare durante il processo, per evitare queste incertezze.
I modelli InstructGPT sono più vicini alle persone rispetto a GPT-3, anche se c’è una grande variabilità all’interno del termine “umani” che non si riflette nel comportamento di InstructGPT. Il modello è in linea con le preferenze dei classificatori e dei ricercatori OpenAI, e quindi l’organizzazione nel suo complesso, ma il resto del mondo? In una discussione, l’azienda ha riconosciuto il problema: “Non stiamo sostenendo che i ricercatori, i classificatori che abbiamo assunto, o i nostri clienti API siano la giusta fonte di preferenze”.
Per diminuire le distorsioni nell’allineamento, OpenAI ha stabilito una serie di criteri di selezione per i classificatori. Il requisito più importante era che i classificatori fossero sensibili alle preferenze dei vari gruppi demografici.
Però è abbastanza improbabile che questo insieme di classificatori rifletta la diversità della nostra società. Inoltre, impiegare un valore medio per determinare l’allineamento sarebbe il contrario dell’allineamento reale, che implica che il modello conosca le preferenze individuali e di gruppo proprio per come differiscono da quelle di altre persone e gruppi. Poiché la maggioranza ha più peso nella scelta finale del modello, l’allineamento medio potrebbe confondere le preferenze delle minoranze.
Creare un modello allineato con un sottogruppo di persone è innegabilmente un passo significativo verso modelli più sicuri e affidabili. Tuttavia, dobbiamo ricordare che gli esseri umani sono incredibilmente diversi quando si lavora sull’allineamento dell’I.A. Come possiamo garantire che un modello di I.A. sia allineato con tutti quelli con cui interagisce in modo non dannoso? Come sostiene OpenAI, l’unico punto di partenza logico è avere almeno un classificatore che rappresenti ogni gruppo, o un modello adatto ad ogni gruppo.
Tuttavia, sorgono altre questioni, come per esempio la definizione dei gruppi? In base all’etnia, al sesso, all’età, al paese, alla religione eccetera. Come ci assicuriamo che i modelli progettati per un certo gruppo non abbiano un impatto negativo sulla società nel suo complesso? Questi sono problemi senza risposta, e dovrebbero essere considerati a fondo prima di usare modelli di parte in nome dell’allineamento.
Si è scelto di testare i modelli tramite TruthfulQA, uno standard che analizza “come i modelli imitino le menzogne umane”, per vedere quanto sono “onesti”. Hanno quindi scoperto che InstructGPT fornisce il doppio delle risposte accurate rispetto a GPT-3. Hanno poi anche messo i modelli alla prova in operazioni di Domande e Risposte, scoprendo che InstructGPT si confonde la metà di GPT-3 (21% vs 41%). I risultati sono che i modelli non hanno bisogno di essere addestrati a comportarsi onestamente, il che solleva l’utente dalla responsabilità di garantire che i modelli siano adeguatamente sollecitati.
Hanno testato i modelli con il dataset RealToxicityPrompts per vedere quanto fossero dannosi scoprendo che InstructGPT è meno dannoso di GPT-3 quando gli viene detto di essere rispettoso, particolarmente dannoso quando non gli viene detto, e sostanzialmente più dannoso quando gli viene detto di essere di parte. Questo significa che coloro che vogliono evitare gli effetti tossici saranno in grado di farlo più efficacemente con InstructGPT, ma quelli con intenzioni maligne troveranno più semplice ferire gli altri con InstructGPT.
Il nuovo modello non è necessariamente più sicuro del GPT-3, ma è maggiormente capace di seguire l’obiettivo dell’utente, il che non è sempre un bene. Aumentare la capacità dei modelli è un passo avanti in termini di prestazioni, ma non sempre in termini di sicurezza. Quindi può essere più facile creare contenuti convincenti e fuorvianti o malevoli e offensivi usando questi modelli.
Questi risultati supportano l’ipotesi che allineare InstructGPT a un gruppo molto ristretto di persone non migliori il suo atteggiamento verso le minoranze e i gruppi discriminatori. Pertanto, classificatori diversi porterebbero a un risultato diverso.
Infine, i ricercatori hanno scoperto che i modelli messi a punto per ottimizzare l’allineamento con classificatori umani soffrono di una penalizzazione delle prestazioni nota come “tassa di allineamento”. Di conseguenza, InstructGPT supera GPT-3 su vari dataset pubblici di elaborazione del linguaggio naturale. Hanno poi rivisto la tecnica di perfezionamento e stabilito il modello PPO-ptx per compensare il calo delle prestazioni. Così l’apprendimento per rinforzo viene usato per mettere a punto questo modello integrando le inclinazioni del modello di ricompensa con gli aggiornamenti dei dati originali usati per pre-addestrare GPT-3. Come risultato, PPO-ptx (InstructGPT) è più abile nei benchmark di elaborazione del linguaggio naturale rispetto al fratello PPO, ma è meno allineato.
In definitiva, InstructGPT non è esente da difetti. Può disobbedire agli ordini, avere allucinazioni, produrre output dannosi e distorti, e offrire risposte estese a brevi domande… Gli stessi problemi che affliggevano i modelli GPT-3 continuano a colpire la versione InstructGPT (i problemi legati alle prestazioni sono meno comuni, ma i problemi legati alla sicurezza, alla dannosità e alla distorsione potrebbero essere più comuni).
Pro e contro
InstructGPT supera GPT-3 in termini di prestazioni. Non in termini di benchmark di elaborazione del linguaggio naturale (dove GPT-3 spesso supera InstructGPT), ma è meglio adattato alle preferenze umane, che è un indicatore più forte delle prestazioni del mondo reale. Grazie ad un modello di apprendimento per rinforzo che gli permette di imparare dal feedback umano, InstructGPT è meglio allineato con l’obiettivo umano.
Non c’è bisogno di connettersi con InstructGPT attraverso strategie di istruzioni implicite o indirette, in quanto può seguire istruzioni esplicite. Questo alleggerisce lo sforzo degli utenti che non hanno familiarità con il funzionamento dei modelli linguistici generativi. Questo è un approccio verso una maggiore democratizzazione di questi modelli (anche se rimangono altre barriere come l’alto costo e la non disponibilità in alcuni paesi).
InstructGPT supera GPT-3 quando si tratta di eseguire istruzioni implicite, rendendolo più accurato, utile e sicuro finché l’utente lo desidera. Quando gli viene richiesto di essere rispettoso, è anche meno dannoso di GPT-3. Questi attributi lo rendono più utile per gli individui ben intenzionati che saranno in grado di ottenere il massimo dal modello mentre saranno meno preoccupati degli errori involontari.
Tuttavia, un cattivo utente potrebbe sfruttare questo per rendere il modello meno accurato e utile, oltre che più pericoloso. Il danno potrebbe essere maggiore poiché il modello è più potente di GPT-3.
InstructGPT può essere più dannoso se viene istruito ad essere di parte per la stessa ragione. Quando gli si chiede di esserlo, l’aumento della dannosità è maggiore di quando si chiede di essere rispettoso. In generale, i modelli sono più distorti di GPT-3. Una spiegazione probabile è perché, come suggeriscono gli autori, InstructGPT è più sicuro delle sue risposte indipendentemente dall’uso di stereotipi. Un altro problema potrebbe essere che l’allineamento del modello con un insieme di persone lo fa disallineare dagli altri, il che si riflette nella valutazione del benchmark.
Infine, alcuni hanno criticato OpenAI per aver classificato lo studio come un documento di “allineamento”, sostenendo che il perfezionamento umano non sia un vero allineamento. Un’altra critica, più seria, riguarda invece l’allineamento del modello con i classificatori assunti: I ricercatori OpenAI e gli utenti OpenAI, non rappresenta un vero allineamento. La vera sfida è addestrare i modelli ad affrontare circostanze in cui i gruppi sono in disaccordo nelle loro preferenze (piuttosto che trovare medie comuni), specialmente quando sono a rischio le minoranze, per via di pregiudizi, che sono sempre prese di mira da questi modelli.
Quando si tratta di Intelligenza Artificiale e di addestramento è sempre difficile trovare l’obiettività quando si parla di valori come l’onestà o quando dobbiamo trovare la dannosità in alcuni comportamenti. Anche se potremmo provare a rilevare le buone e le cattive intenzioni addestrando l’A.I. attraverso gli esseri umani, inevitabilmente falliremo perché le persone stesse non possono essere obiettive tutto il tempo e non possiamo nemmeno trovare il campione perfetto di persone che rappresentano bene ciò che è giusto o sbagliato. Quindi forse abbiamo bisogno di un addestramento continuo da parte di persone diverse, sperando che il raggiungimento di un’umanità sempre migliore converga in un migliore addestramento dell’I.A.
Fonte towardsdatascience.com
