
Una startup sta scoprendo come funzionano le reti neurali
Anthropic PBC, una startup che si occupa di intelligenza artificiale, sostiene di aver sviluppato una tecnica per comprendere meglio il comportamento delle reti neurali che guidano i suoi algoritmi di IA.
Come riportato qui, lo studio potrebbe avere effetti significativi sull’affidabilità e la sicurezza delle future IA, consentendo a ricercatori e sviluppatori un maggiore controllo sul comportamento dei loro modelli. Lo studio esamina il comportamento imprevedibile delle reti neurali, che sono modellate sul cervello umano e imitano il modo in cui i neuroni organici comunicano tra loro.
Le reti neurali costruiscono modelli di intelligenza artificiale che possono esibire una gamma sconcertante di comportamenti, poiché vengono istruiti in base ai dati piuttosto che essere programmati per seguire delle regole. Sebbene la matematica alla base di queste reti neurali sia ampiamente compresa, non è chiaro perché le operazioni matematiche che eseguono portino a particolari comportamenti. Ciò significa che è incredibilmente difficile gestire i modelli di IA e fermare le cosiddette “allucinazioni“, in cui i modelli di IA forniscono occasionalmente risultati falsi.
Secondo Anthropic, i neuroscienziati incontrano difficoltà analoghe quando cercano di comprendere le cause biologiche del comportamento umano. Sono consapevoli che i pensieri, i sentimenti e i processi decisionali delle persone devono essere implementati in qualche modo dai neuroni che sparano nel loro cervello, ma non sono in grado di determinare come ciò avvenga.
“I singoli neuroni non hanno relazioni coerenti con il comportamento della rete”, ha spiegato Anthropic. “Per esempio, un singolo neurone in un piccolo modello linguistico è attivo in molti contesti non correlati, tra cui citazioni accademiche, dialoghi in inglese, richieste HTTP e testi in coreano. In un modello di visione classico, un singolo neurone risponde ai volti dei gatti e ai frontali delle automobili. L’attivazione di un neurone può avere significati diversi in contesti diversi”.
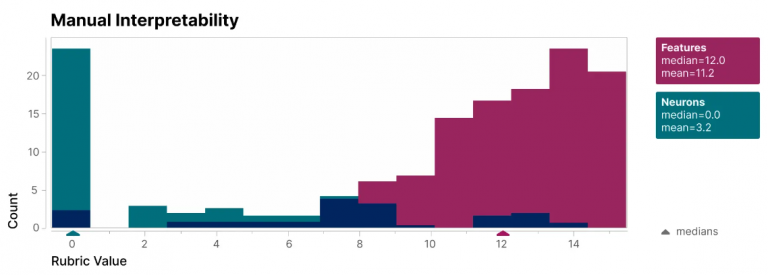
I ricercatori di Anthropic hanno esaminato i singoli neuroni in modo più dettagliato per capire meglio cosa fanno le reti neurali. Hanno affermato di aver trovato piccole unità, note come caratteristiche, all’interno di ciascun neurone che corrispondono maggiormente ai modelli di attivazione dei neuroni. I ricercatori sperano che, esaminando queste particolari qualità, saranno in grado di capire come funzionano le reti neurali.
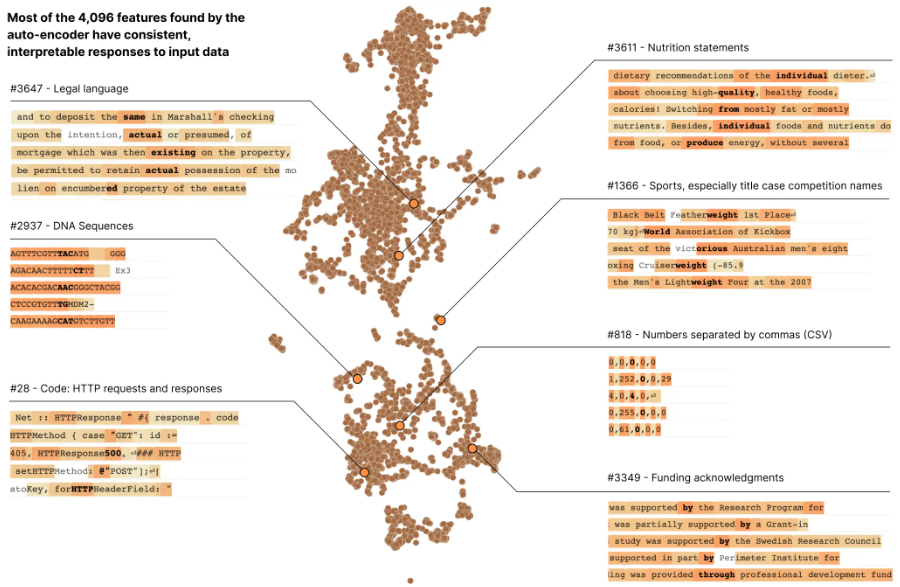
Anthropic ha analizzato in un esperimento un modesto modello linguistico trasformatore, scomponendo 512 neuroni artificiali in più di 4.000 caratteristiche che rappresentano situazioni come sequenze di DNA, terminologia legale, richieste HTTP, testo ebraico, indicazioni nutrizionali e altro ancora. Hanno così scoperto che il comportamento delle singole caratteristiche poteva essere compreso molto più facilmente del comportamento dei neuroni.
Questo, secondo Anthropic, offre una prova convincente del fatto che le caratteristiche possono servire come base per la comprensione delle reti neurali. Zoomando ed esaminando l’intera collezione, Anthropic ha scoperto che ognuna delle oltre 4.000 caratteristiche è principalmente condivisa da diversi modelli di intelligenza artificiale. Di conseguenza, le conoscenze acquisite esaminando le caratteristiche di un modello possono essere applicate ad altri.
Anthropic ritiene che, con ulteriori studi, sia possibile manipolare queste qualità per regolare il comportamento delle reti neurali in modo più prevedibile. Alla fine, potrebbe essere cruciale superare la difficoltà a capire perché i modelli linguistici agiscono nel modo in cui agiscono.

“Speriamo che questo ci consenta di monitorare e guidare il comportamento dei modelli dall’interno, migliorando la sicurezza e l’affidabilità essenziali per l’adozione da parte delle imprese e delle società”, hanno dichiarato i ricercatori.
Le reti neurali sono ormai straordinariamente complesse che risulta difficile analizzarle nella loro interezza, anche per via della mole di informazioni che racchiudono e che necessiterebbero di vite intere per poterle studiare esclusivamente sfruttando la capacità umana. Possiamo capirne la logica, ma abbiamo bisogno di altri strumenti per capirle a fondo. Lo studio di Anthropic permetterà di avere un migliore visione delle reti neurali in futuro e di poter intervenire in maniera più specifica sul loro comportamento permettendo di correggere eventuali anomalie che la cui origine risultava meno chiara precedentemente.