

A startup is discovering how neural networks work
Anthropic PBC, a startup in artificial intelligence, claims to have developed a technique to better understand the behavior of the neural networks that drive its AI algorithms.
As reported here, the study may have significant effects on the dependability and security of future AI, allowing researchers and developers more control over the course of their models’ behavior. It examines the unpredictable behavior of neural networks, which are modeled after the human brain and imitate how organic neurons communicate with one another.
Neural networks build AI models that can exhibit a bewildering variety of behaviors since they are taught on data rather than being programmed to follow any rules. Although the mathematics underlying these neural networks is widely understood, it is unclear why the mathematical operations they carry out lead to particular behaviors. This means it’s incredibly challenging to manage AI models and stop what’s known as “hallucinations“, in which AI models occasionally provide false results.
According to Anthropic, neuroscientists encounter comparable difficulty while trying to understand the biological causes of human behavior. They are aware that people’s thoughts, feelings, and decision-making must be implemented in some way by the neurons firing in their brains, but they are unable to determine how this is done.
“Individual neurons do not have consistent relationships with network behavior”, Anthropic explained. “For example, a single neuron in a small language model is active in many unrelated contexts, including academic citations, English dialogue, HTTP requests, and Korean text. In a classic vision model, a single neuron responds to faces of cats and fronts of cars. The activation of one neuron can mean different things in different contexts”.
Anthropic’s researchers examined the individual neurons in greater detail to have a better understanding of what neural networks are doing. They claimed to have found little units, known as features, within each neuron that more closely match patterns of neuron activation. The researchers hope that by examining these particular qualities, they will eventually be able to understand how neural networks work.
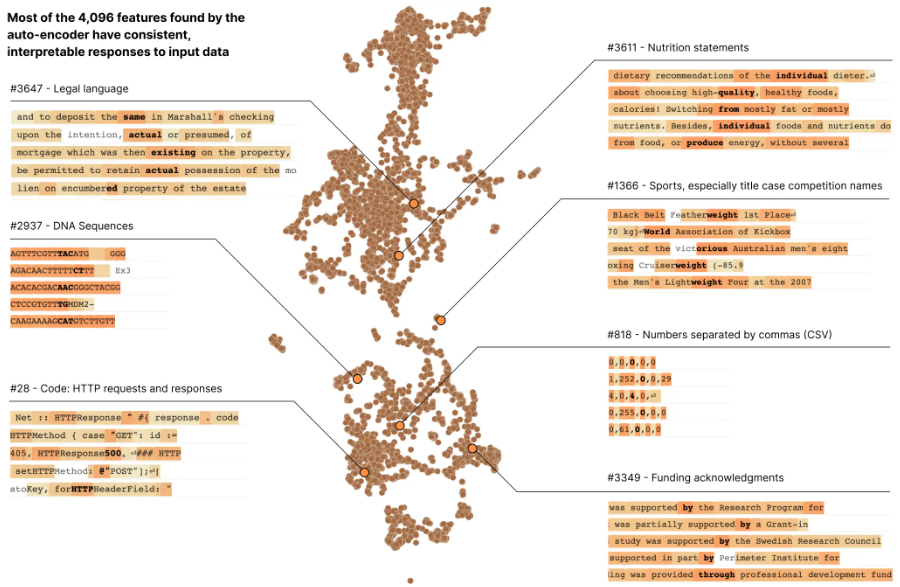
Anthropic investigated a modest transformer language model in an experiment, breaking down 512 artificial neurons into more than 4,000 features that stand in for settings like DNA sequences, legal terminology, HTTP requests, Hebrew text, nutrition claims, and more. They discovered that the behavior of the individual features could be understood far more easily than the behavior of the neurons.
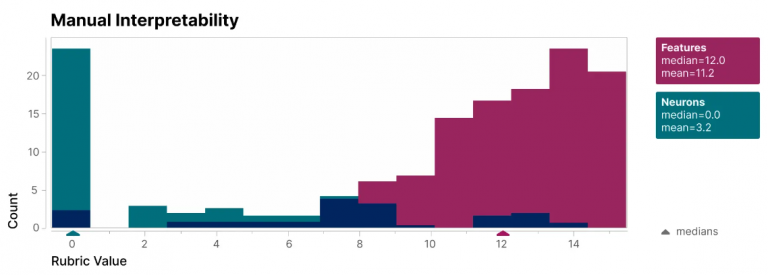
This, according to Anthropic, offers convincing proof that features can serve as the foundation for neural network comprehension. Anthropic found that every one of the 4,000+ features is primarily shared by various AI models by zooming out and examining the complete collection. As a result, the knowledge gained by examining the characteristics of one model can be applied to others.
Anthropic thinks it may be possible to manipulate these qualities to regulate the behavior of neural networks in a more predictable manner with further study. In the end, it might be crucial to overcome the difficulty of understanding why language models act the way they do.

“We hope this will eventually enable us to monitor and steer model behavior from the inside, improving the safety and reliability essential for enterprise and societal adoption”, the researchers said.
Neural networks are now so extraordinarily complex that it is difficult to analyze them in their entirety, partly because of the amount of information they encapsulate that would require entire lifetimes to study using exclusively human capacity. We can understand their logic, but we need other tools to understand them thoroughly. Anthropic’s study will provide a better view of neural networks in the future and allow us to intervene more specifically in their behavior by allowing us to correct any anomalies whose origin was less clear previously.
