

It takes just 3 seconds to clone a voice
Microsoft researchers have developed a new text-to-speech AI model called VALL-E that can accurately mimic a person’s voice with just a 3-second audio sample. VALL-E can synthesize audio of anyone once it learns their voice, and it does it in a way that tries to capture their emotional tone.
According to its developers and as explained here, VALL-E could be combined with other generative AI models like GPT-3 to create audio content and be used for high-quality text-to-speech applications, speech editing, which would allow a person’s voice to be changed and edited from a text transcript (making them say something they didn’t originally say).
VALL-E, which Microsoft refers to as a “neural codec language model”, is based on a technology known as EnCodec that Meta unveiled in October 2022. VALL-E produces discrete audio codec codes from text and acoustic prompts, in contrast to conventional text-to-speech systems that typically synthesize speech by modifying waveforms. According to Microsoft’s VALL-E paper, it essentially analyzes how a person sounds, breaks that information into discrete components (referred to as “tokens”) using EnCodec and then uses training data to match what it “knows” about how that voice would sound if it spoke other phrases outside of the three-second sample.
Microsoft used LibriLight, an audio library put together by Meta, to train VALL-E’s voice synthesis skills. The majority of the 60,000 hours of English-language speech are taken from LibriVox public domain audiobooks and are spoken by more than 7,000 different people. The voice in the three-second sample must closely resemble a voice in the training data for VALL-E to get a satisfactory result. Microsoft offers dozens of audio examples of the AI model in action on the VALL-E example page.
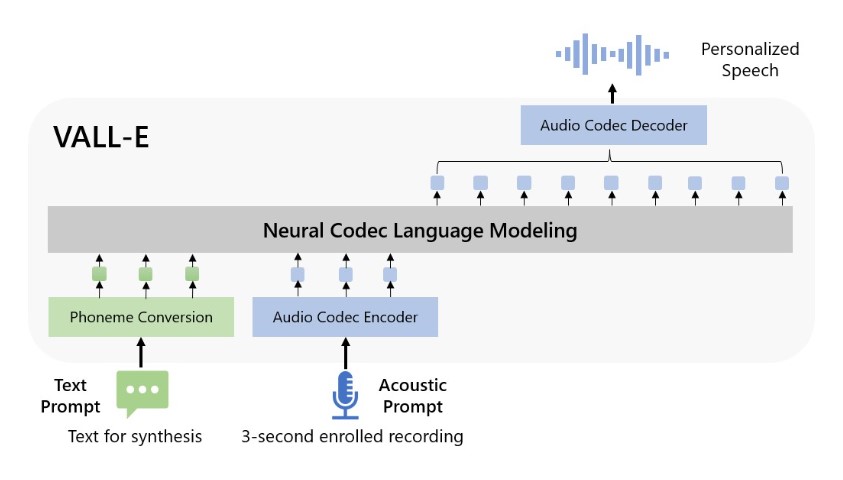
The researchers just provided VALL-E the three-second sample and a text string (what they intended the voice to say) in order to produce those findings. If you compare some samples you can see they are remarkably similar in certain instances. The purpose of the model is to produce results that may be mistaken for human speech, even though some VALL-E outcomes still appear to be computer-generated.
The “acoustic environment” of the sample audio can be replicated by VALL-E in addition to maintaining the vocal timbre and emotional tone of the speaker. The audio output, for instance, will imitate the acoustic and frequency characteristics of a telephone call in its synthesized output if the sample originated from a call. Additionally, Microsoft’s samples (shown in the “Synthesis of Diversity” section) demonstrate how VALL-E can produce different voice tones by altering the random seed employed during generation.
A random seed is a value that is used to initialize a random number generator in machine learning. This value is used to generate a series of random numbers that can be employed at several points throughout the machine-learning process, such as when setting the initial weights in a neural network or creating fictitious data.
The purpose of employing a random seed is to guarantee that the same set of random numbers is created each time the code is executed, allowing the machine-learning algorithm to provide repeatable results. Without a seed, each time the code is executed, a distinct series of random numbers are generated by the random number generator, making it challenging to compare or duplicate experiment results.
It’s crucial to keep in mind that in practice, even with the same seed, different systems or versions of programming languages may produce different random numbers, making them less deterministic than it appears.

Microsoft has not made the VALL-E code available for others to experiment with though, possibly due to VALL-E’s potential to cause trouble and deception. The potential social harm that this technology can do seems to be recognized by the researchers. In fact, they state in the paper’s conclusion:
“Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. To mitigate such risks, it is possible to build a detection model to discriminate whether an audio clip was synthesized by VALL-E. We will also put Microsoft AI Principles into practice when further developing the models”.
We are on a path already traced. Some AI developments we had anticipated are now happening but at a higher speed. We started with the risks of Deepfakes and now we’re going to face the consequences of cloning voices. In the next future, the power of AI will unsettle the world and many people will risk many deceits, especially those about their identity. Deepfakes and voice cloning will be the next social engineering bad actors could use to steal identities or to make fake pieces of evidence. And with the power of Quantum Computing probably any password could be violated. It was sufficient to see what ChatGPT is causing in the world of creators to understand how the world can quickly change.

[…] Source […]