

Ci vogliono solo 3 secondi per clonare una voce
I ricercatori di Microsoft hanno sviluppato un nuovo modello di intelligenza artificiale text-to-speech chiamato VALL-E, in grado di imitare accuratamente la voce di una persona con un campione audio di soli 3 secondi. VALL-E è in grado di sintetizzare l’audio di chiunque una volta appresa la sua voce, e lo fa cercando di catturare anche il suo tono emotivo.
Secondo i suoi sviluppatori e come qui riportato, VALL-E potrebbe essere combinato con altri modelli di intelligenza artificiale generativa, come GPT-3, per creare contenuti audio ed essere utilizzato per applicazioni text-to-speech di alta qualità, ma anche per l’editing vocale, che consentirebbe di cambiare e modificare la voce di una persona a partire da una trascrizione testuale (facendole dire qualcosa che non ha detto in origine).
VALL-E, che Microsoft definisce “modello linguistico con codec neurale”, si basa su una tecnologia nota come EnCodec, presentata da Meta nell’ottobre 2022. VALL-E produce codici codec audio discreti a partire dal testo e dai suggerimenti acustici, a differenza dei sistemi text-to-speech convenzionali che in genere sintetizzano il parlato modificando le forme d’onda. Secondo il documento di Microsoft, VALL-E analizza essenzialmente il modo in cui una persona suona, scompone queste informazioni in componenti discreti (denominati “token”) utilizzando EnCodec e poi utilizza i dati di addestramento per abbinare ciò che “sa” su come suonerebbe quella voce se pronunciasse altre frasi al di fuori del campione di tre secondi.
Per addestrare le capacità di sintesi vocali di VALL-E, Microsoft ha utilizzato LibriLight, una libreria audio creata da Meta. Così la maggior parte delle 60.000 ore di parlato in lingua inglese sono state prese da audiolibri di pubblico dominio come LibriVox e sono state pronunciate da più di 7.000 persone diverse. Per ottenere un risultato soddisfacente, la voce del campione di tre secondi deve assomigliare molto a una voce presente nei dati di addestramento di VALL-E. Microsoft offre decine di esempi audio del modello di IA in azione nella pagina degli esempi di VALL-E.
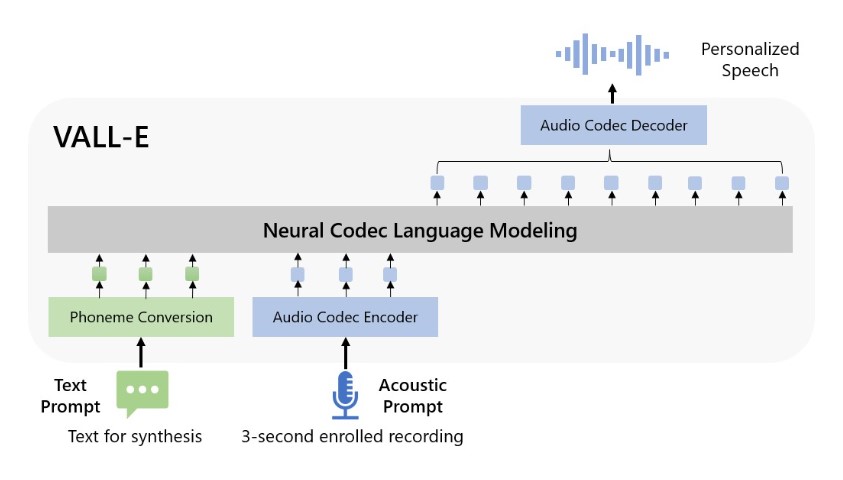
Per produrre questi risultati, i ricercatori hanno semplicemente fornito a VALL-E un campione di tre secondi e una stringa di testo (ciò che intendevano far dire alla voce). Se si confrontano alcuni campioni, si può notare che in alcuni casi sono molto simili. Lo scopo del modello è infatti quello di produrre risultati che possano essere scambiati per il parlato umano, anche se alcuni risultati di VALL-E sembrano ancora essere generati al computer.
L'”ambiente acustico” dell’audio campione può anch’esso essere replicato da VALL-E, in aggiunta al mantenimento del timbro vocale e del tono emotivo dell’oratore. L’output audio, ad esempio, imiterà le caratteristiche acustiche e di frequenza di una telefonata, se il campione proviene da questa. Inoltre, i campioni di Microsoft (illustrati nella sezione “Sintesi della diversità”) dimostrano come VALL-E possa produrre toni vocali diversi modificando il seme casuale utilizzato durante la generazione.
Un seme casuale è un valore utilizzato per inizializzare un generatore di numeri casuali all’interno dell’apprendimento automatico. Questo valore viene utilizzato per generare una serie di numeri casuali che possono essere impiegati in diversi punti del processo di apprendimento automatico, come ad esempio quando si impostano i pesi iniziali di una rete neurale o si creano dati fittizi.
Lo scopo dell’impiego di un seme casuale è quello di garantire che lo stesso insieme di numeri casuali venga creato ogni volta che il codice viene eseguito, consentendo all’algoritmo di apprendimento automatico di fornire risultati ripetibili. Senza un seme, ogni volta che il codice viene eseguito, il generatore di numeri casuali genera una serie diversa di numeri casuali, rendendo difficile il confronto o la duplicazione dei risultati degli esperimenti.
È fondamentale tenere presente che in pratica, anche con lo stesso seme, sistemi o versioni diverse di linguaggi di programmazione possono produrre numeri casuali diversi, rendendoli meno deterministici di quanto sembri.

Microsoft non ha però reso disponibile il codice di VALL-E per la sperimentazione, forse a causa della possibilità che VALL-E possa causare problemi e inganni. I ricercatori sembrano essere consapevoli del potenziale danno sociale che questa tecnologia può provocare. Infatti, nelle conclusioni del documento affermano che:
“Dal momento che VALL-E potrebbe sintetizzare un discorso mantenendo l’identità del parlante, potrebbe comportare rischi potenziali nell’uso improprio del modello, come lo spoofing dell’identificazione vocale o l’impersonificazione di un parlante specifico. Per mitigare tali rischi, è possibile costruire un modello di rilevamento per discriminare se un clip audio è stato sintetizzato da VALL-E. Metteremo in pratica i Microsoft AI Principles anche nell’ulteriore sviluppo dei modelli”.
Siamo su un percorso già tracciato. Alcuni sviluppi dell’IA che avevamo previsto stanno avvenendo ora, ma a una velocità maggiore. Abbiamo iniziato con i rischi dei Deepfakes e ora stiamo per affrontare le conseguenze della clonazione delle voci. Nel prossimo futuro, il potere dell’IA sconvolgerà il mondo e molte persone rischieranno di essere ingannate, soprattutto per quanto riguarda la loro identità. I deepfakes e la clonazione vocale saranno i prossimi strumenti di ingegneria sociale che i malintenzionati potrebbero utilizzare per rubare identità o creare false prove. E con la potenza del Quantum Computing probabilmente qualsiasi password potrà essere violata. È stato sufficiente vedere ciò che ChatGPT sta causando nel mondo dei Creator per capire come il mondo possa cambiare rapidamente.
