
With 3 images, you can see your new haircut
In the last few years, we have been seeing lots of A.I.s able to edit images in various ways, such as by changing global attributes like pose, expression, gender, or age. Another approach to image editing is to select features from reference images (hair, for example) and mix them together to form a single, composite image.
That’s the case with this type of GAN called Barbershop, which can transform not only the style of your hair but also the color, starting from 3 images:
- a picture of yourself;
- a picture of someone with the hairstyle you would like to have;
- another picture (or the same one) of the hair color you would like to try.

The major issue, however, is that the visual properties of various sections of an image are not independent of each other. Ambient and reflected light, as well as transmitted colors from the underlying face, clothing, and background, all have an impact on the aesthetic aspects of hair. The shape of a person’s head and shoulders affects the appearance of their nose, eyes, and mouth, and the geometry of their head and shoulders affects shadows and hair geometry.
Disocclusion of the background, which occurs as the hair region reduces in relation to the background, is another issue. Face disocclusion can reveal new parts of the face, such as the ears, forehead, or jawline. The shape of the hair is determined by the stance as well as the camera’s inherent limitations; therefore, the pose may need to be adjusted to accommodate the hair. Even if each part of the face is synthesized with a high level of realism, failing to account for a picture’s global consistency will result in visible artifacts, and the different sections of the image will appear disjointed.
For example, as mentioned in this article, if you take someone’s hair from a photograph taken in a dark room and try to put it on a head in daylight, it will still seem unnatural, even if it is correctly transposed. Other GAN-based algorithms typically attempt to encode the information in the images and specifically identify the region associated with the hair attributes in order to swap them. When the two photos are taken in similar conditions, it works well, but it won’t seem natural most of the time for the reasons stated.
As a result, they had to use a different network to correct the relighting, holes, and other strange artifacts that the merging had generated. So the goal was to transpose the haircut and color of a specific image onto another image while adjusting the results to follow the lighting and properties of that image to make it realistic and reduce the steps and sources of errors.
Peihao Zhu, who is responsible for the project, achieved this by adding a missing but crucial alignment phase to GANs. Indeed, rather than just encoding and combining the images, it significantly adjusts the encoding using a modified segmentation mask to make the code from the two images more similar.

Convolutions are used by GANs to encode information. This implies it employs kernels to downscale the information at each layer and make it smaller and smaller, reducing spatial features one by one while increasing the value of the general information in the output. This structural data is acquired from the GAN’s early layers before the encoding gets too generic and too encoded to represent spatial aspects.
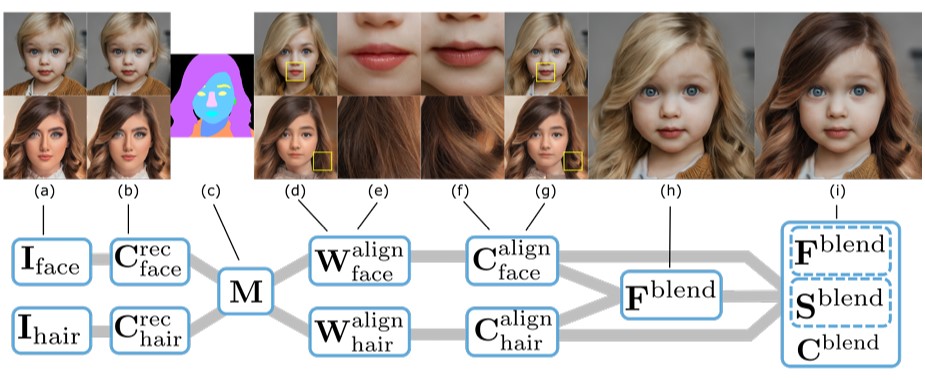
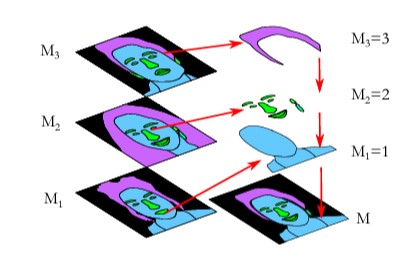
Segmentation maps from the photos are used to generate a more realistic output. And, more specifically, creating this desired new image using an aligned version of the target and reference images. These segmentation maps show us what is in the image and where it is, such as hair, skin, eyes, nose, and so on.

Using this information from the different photos, they can align the heads following the target image before delivering the images to the network for encoding using a modified StyleGAN2-based architecture. This alignment makes it considerably easier to compare and reconstruct the encoded data.
They then identify an acceptable mixture ratio of these appearance encodings from the target and reference images for the identical segmented regions to make it look as authentic as possible for the appearance and illumination problem.

The architecture, like that of other GAN implementations, had to be trained. They employed a StyleGAN2-based network trained on images of the FFHQ dataset in this experiment. Because they made so many changes, they then trained their updated StyleGAN2 network a second time using 198 pairs of photos as hairstyle transfer examples to maximize the model’s choice for both the appearance mixture ratio and the structural encodings.
As you imagine, there are still some flaws in their approach, such as when the segmentation masks aren’t aligned or the face isn’t reconstructed. Nonetheless, the results are excellent.
Barbers and hairdressers will surely adopt this technology in the future to show how their clients look with a certain cut.
